Запуск моделей штучного інтелекту локально на вашому комп'ютері дає більше контролю над даними та не потребує постійного підключення до інтернету. Хоча, для повноцінного користування потужності домашнього ПК буде недостатньо, але спробувати невеликі моделі, на 3-7 мільярдів параметрів, вдасться. Це цікава можливість для розробників та дослідників.
Щоб запустити модель ШІ локально на вашому ПК з Windows, вам знадобляться наступні два інструменти:
- Ollama – платформа яка надає можливість завантажувати та використовувати різні моделі штучного інтелекту (великі мовні моделі LLM) безпосередньо в терміналі операційної системи.
- Docker – програмне забезпечення, яке дозволяє створювати та запускати програми в ізольованих середовищах, які називаються контейнерами.
У цій статті я поясню, як на своєму ПК локально запустити модель ШІ, створивши контейнер у програмі Docker. Для прикладу я візьму модель Qwen AI, а саме Qwen2.5 3b та 7b, та chatgph/gph-main.
Як встановити Ollama
Спочатку необхідно встановити Ollama у систему. Це спростить подальше встановлення, налаштування та керування великими мовними моделями. Дотримуйтесь наведених нижче кроків:
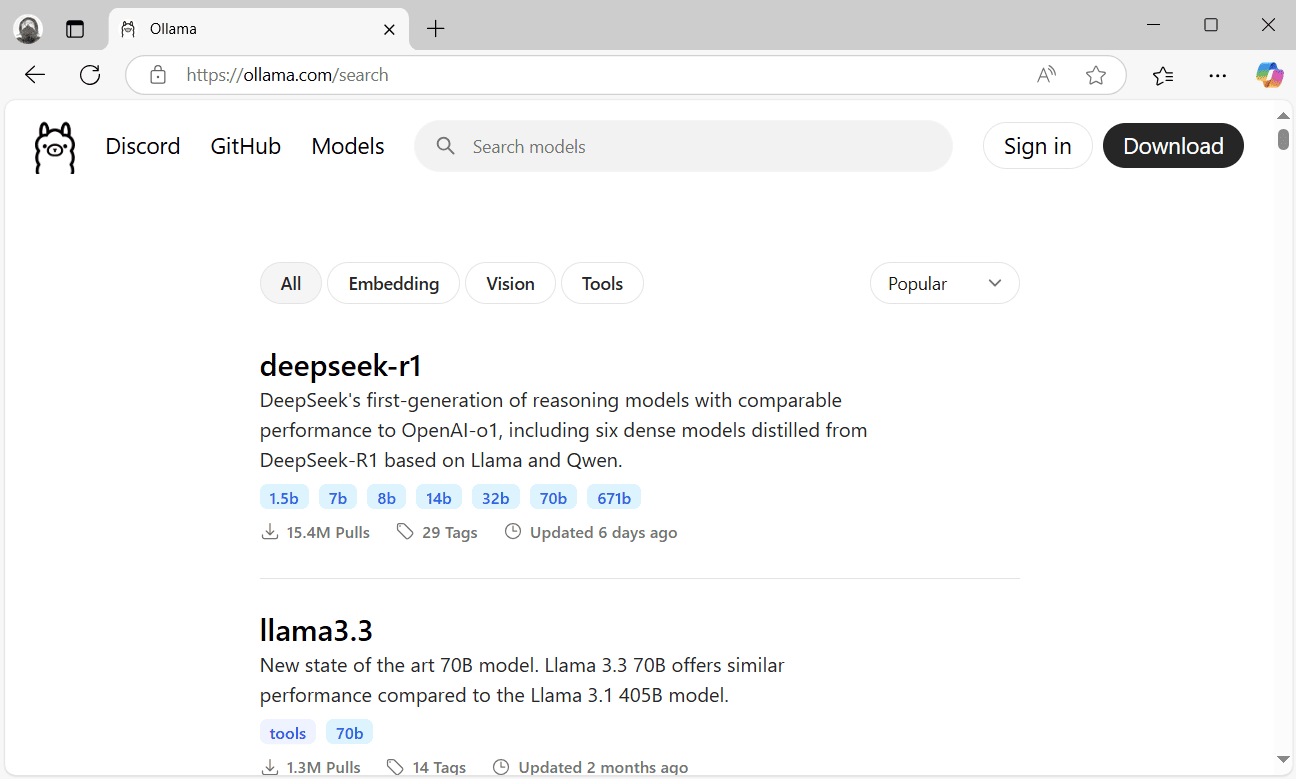
- Перейдіть на офіційний сайт ollama.com
- Натисніть кнопку «Download» та завантажте інсталяційний пакет.
- Після завершення завантаження встановіть Ollama в систему та дозвольте програмі працювати у фоні.
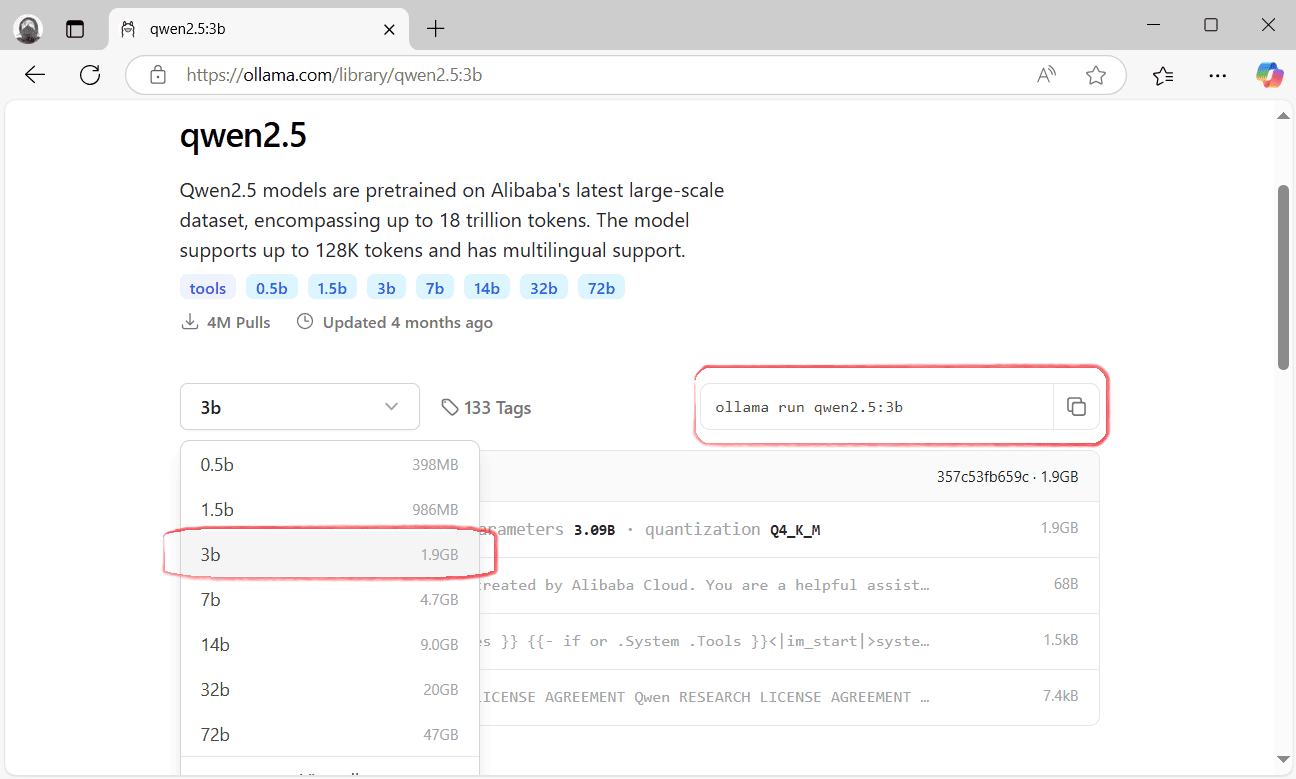
- Знову зайдіть на сайт Ollama та перейдіть у розділ «Models». Тут зібрані всі доступні моделі штучного інтелекту. В списку, чи через пошук, знайдіть «qwen2.5».
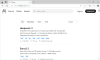
- Зі спадного списку виберіть варіант моделі який хочете розгорнути на своєму комп’ютері, наприклад, «3b» на 3.09 мільярдів параметрів. Скопіюйте команду для встановлення вибраної моделі.
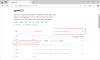
- Відкрийте командний рядок та вставте попередньо скопійовану команду.
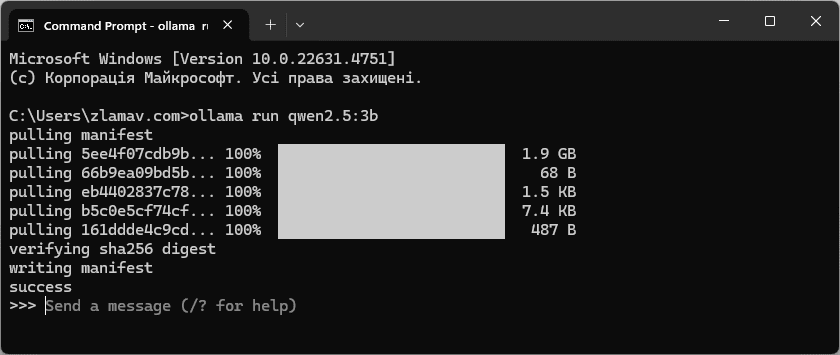
ollama run qwen2.5:3b
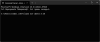
- Дочекайтесь коли модель ШІ буде завантажена та встановлена у систему.
Щоб встановити іншу модель ШІ, скопіюйте потрібну команду з сайту Ollama та запустіть її в командному рядку. Тобто, пройдіть ще раз кроки 4-7.
Встановлення Docker
Користуватися встановленою моделлю ШІ можна у командному рядку. Однак в такому випадку не зберігається історія чату та це не зовсім зручно. Docker встановить спеціальний інтерфейс користувача, що значно спрощує його використання.
- Перейдіть на офіційний сайт docker.com (бажано створити обліковий запис).
- Завантажте Docker та встановіть на свою систему. Переконайтеся, що він продовжує працювати у фоновому режимі.
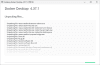
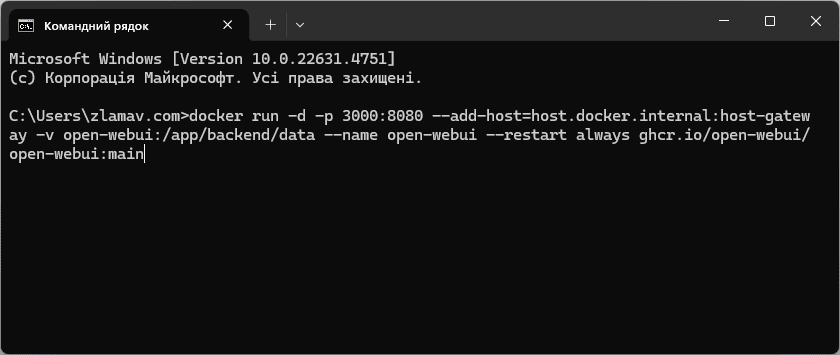
- Відкрийте командний рядок та виконайте наступну команду
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
Ця команда створить контейнер у додатку Docker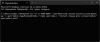
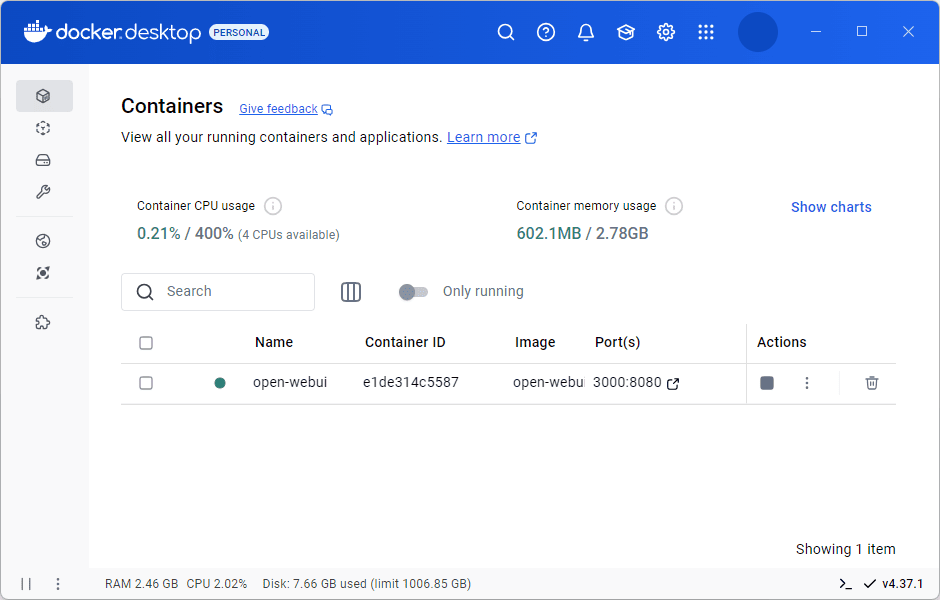
- Команда буде виконуватися певний час. Коли всі компоненти завантажаться та встановляться запустіть Docker.
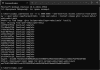
- У розділі «Containers» буде відображатися створений контейнер. Тепер, щоб запустити локально встановлену модель «qwen2.5», натисніть на посилання «3000:8080» у розділі створеного контейнера.
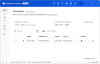
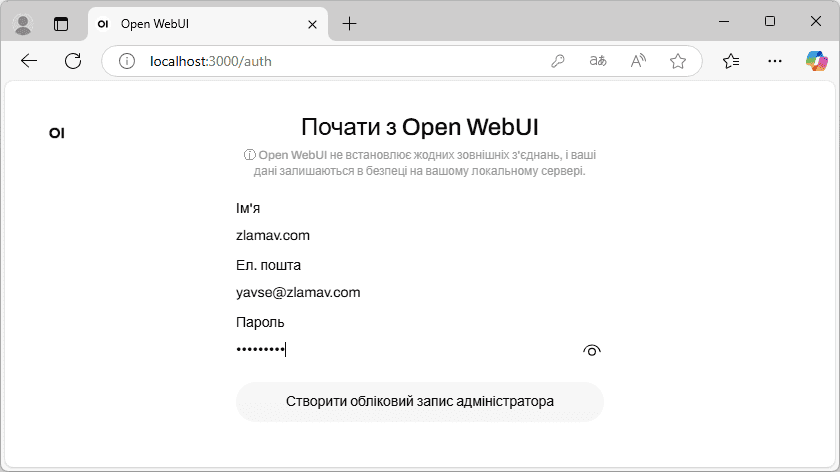
- У вашому типовому веб-браузері відкриється локальний хост з портом 3000. Створіть обліковий запис адміністратора вказавши ім’я, ел.пошту та пароль.

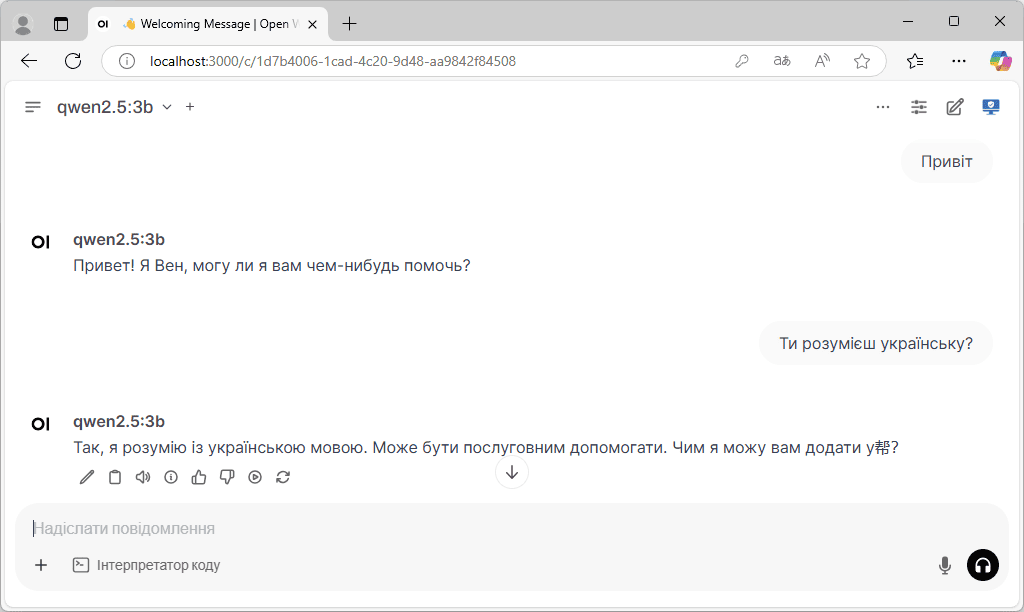
- Тепер можна користуватися ШІ локально. Якщо моделей декілька, вибрати необхідну можна зліва у меню.
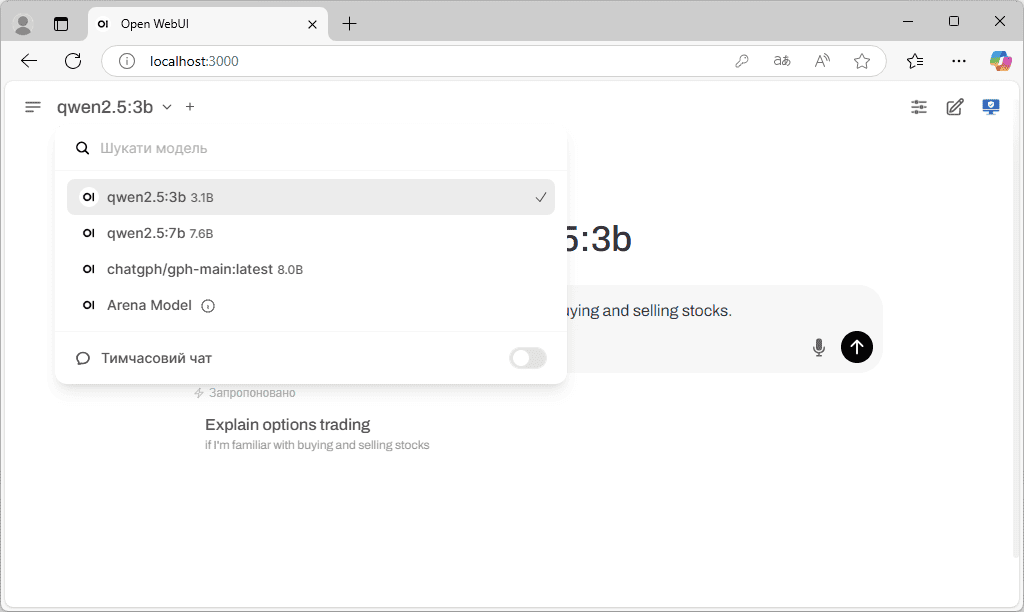
Зверніть увагу, що для локального запуску моделі штучного інтелекту, як Ollama, так і контейнер Docker повинні працювати у фоновому режимі.
Вимоги до комп’ютера
Продуктивність моделі ШІ значною мірою залежить від обладнання, на якому вона працює. Якщо відкинути всі технічні терміни то для невеликих моделей 0.5b – 7b достатньо буде домашнього ПК середньої потужності. А от для моделей з сотнями мільярдів параметрів знадобляться потужні сервери.
Комп'ютер для роботи з моделями LLaMA та LLama-2 (з параметрами 7b) для версії GPTQ має мати принаймні 6 Гб відеопам'яті. А ось для формату GGML/GGUF мова йде скоріше про наявність достатнього об’єму оперативної пам'яті. Швидкість оперативної пам'яті також має велике значення так як вона впливає на обробку запитів. Великі мовні моделі повинні повністю завантажуватися в RAM або VRAM.
Наприклад, оперативна пам'ять DDR4-3200 з теоретичною максимальною пропускною здатністю 50 Гбіт/с зможе генерувати приблизно 9 токенів на секунду. Щоб досягти вищої швидкості, скажімо, 16 токенів на секунду, знадобиться більша пропускна здатність. Система з DDR5-5600 пропонує близько 90 Гбіт/с, а DDR5-6400 зможе забезпечити до 100 Гбіт/с. Для порівняння, сучасні графічні процесори, такі як NVIDIA RTX 3090, мають майже 930 Гбіт/с пропускної здатності для своєї відеопам'яті.
Для найкращої продуктивності вибирайте ПК з потужним графічним процесором (наприклад, RTX 3090 або RTX 4090 від NVIDIA) або подвійним графічним процесором для моделей 65b чи 70b. Оптимальною буде система з достатнім обсягом оперативної пам'яті (мінімум 16 Гб, але краще 64 Гб). Для процесора гарним вибором буде Intel Core i7 від 8-го покоління або AMD Ryzen 5 від 3-го покоління з 6-ядерами (краще 8-ядерний).
Для бюджетного варіанту зосередьтеся на моделях GGML/GGUF, які використовують лише оперативну пам'ять системи, хоча це й призводить до втрати продуктивності. Процесор має бути сучасний багатоядерний.
В цій статті я встановив, а точніше намагався встановити, три моделі ШІ: Qwen2.5 3b та 7b, chatgph/gph-main. З них запрацювала лише Qwen2.5 3b. Інші дві встановити не вдалося через недостачу оперативної пам’яті.
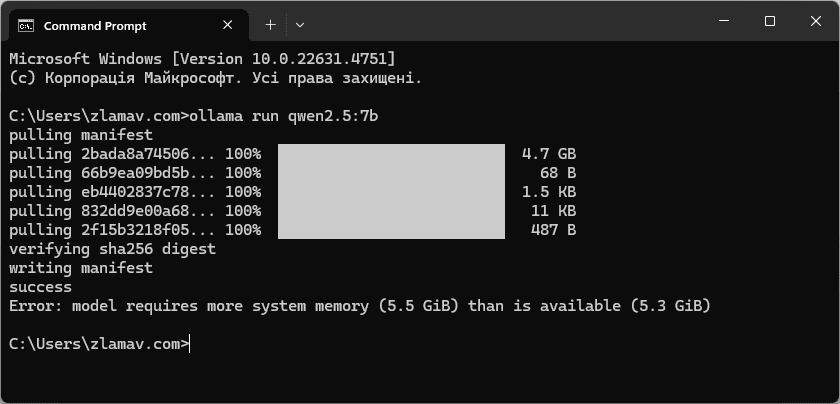
Тест проводив на системі:
- Процесор: Intel Core i3-4170 3.70 ГГц
- ОЗП: 4+2 Гб, 1600 МГц
- Накопичувач: SSD ADATA SU650 240 Гб
- ОС: Windows 11 Pro 23H2
